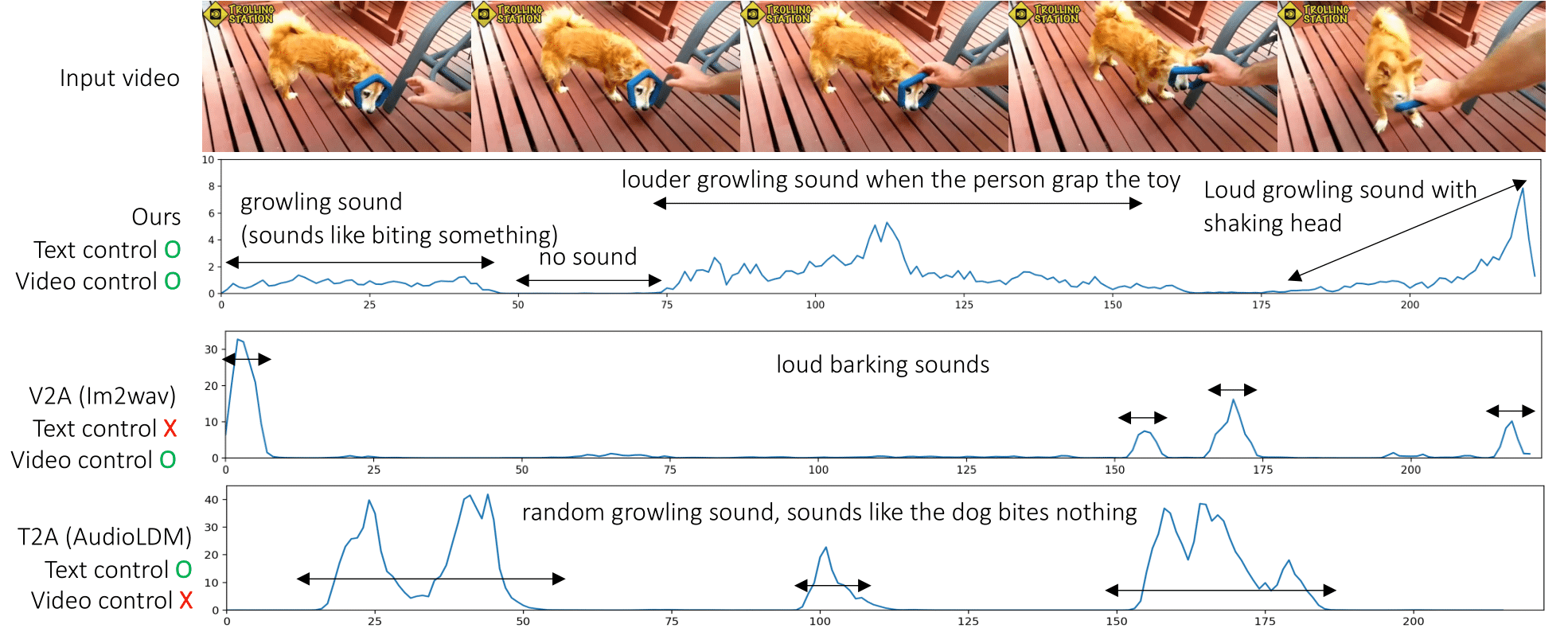
The text instruction ``dog growling'' is used for the text control. The video-to-audio (V2A) or text-to-audio (T2A) generation methods cannot understand the detailed semantics from texts (the dog is growling, not barking) or video (the dog is biting something, and the alignment), respectively.
Abstract
Multimodal generative models have shown impressive advances with the help of powerful diffusion models. Despite the progress, generating sound solely from text poses challenges in ensuring comprehensive scene depiction and temporal alignment. Meanwhile, video-to-sound generation limits the flexibility to prioritize sound synthesis for specific objects within the scene. To tackle these challenges, we propose a novel video-and-text-to-sound generation method where video serves as a conditional control for a text-to-sound generation model. Our method estimates the structural information of sound (namely, energy) from the video while receiving key content cues from a user prompt. We employ a well-performing text-to-sound model to consolidate the video control, which is much more efficient for training multimodal diffusion models with massive triplet-paired (audio-video-text) data. In addition, by separating the generative components of sounds, it becomes a more flexible system that allows users to freely adjust the energy, surrounding environment, and primary sound source according to their preferences. Experimental results demonstrate that our method shows superiority in terms of quality, controllability, and training efficiency.
Generation Results
Temporal Alignment
ReWaS can capture small movement , short transition and silent moment.
|
|
Prompt: lions growling
|
Prompt: skateboarding
|
Prompt: alarm clock ringing
|
Effectiveness of Video Condition
Temporal alignment information from the video are transferred through energy control. 1. Even if there is missing information in the text prompt, the energy control complements this. 2. Different video events generate sounds with different rhythms and tempos.
|
|
Prompt: car engine
|
Prompt: darts
|
Prompt: sea lion
|
|
|
Sound: 🔊 Car engine + 🔊 Spray
|
Sound: 🔊 darts + 🔊 people talking
|
Sound: 🔊 1. sea lion + 🔊 2. sea lion
|
General User Prompt
Users can generate sound using any text prompt. The videos and prompts used are from Kling.
|
|
Prompt: A chef is cutting onions in a kitchen, preparing for the dish.
|
Prompt: A rally car swiftly navigates a turn on the racetrack.
|
Prompt: In an ornate, historical hall, a massive tidal wave peaks and begins to crash. Two surfers, seizing the moment, skillfully navigate the face of the wave.
|
Comparison with Baselines
|
|
Prompt: dog growling
|
Prompt:people screaming
|
Prompt: orchestra
|
|
|
Prompt: car engine starting
|
Prompt: Sharpen knife
|
Prompt: playing banjo
|
|
|
Prompt: cat growling
|
Prompt: canary calling
|
Prompt: chainsawing trees
|